TPOT: Automate Your Machine Learning Training Process
Stop rewriting the same code for model selection and hyper-parameter search


Let’s face it — model training is extremely time-consuming. What if you could automate it?
Meet TPOT, your data science assistant. It saves you time and effort in looking for the most optimized machine learning pipeline.
Give TPOT the data, and it will give you the code for the most optimized machine learning algorithm based on the familiar sklearn.
This blog post covers an introduction to TPOT and some sample code. Read on.
Why should you automate your machine learning optimization process?
You have an exciting set of data that has the potential for machine learning. You explored every nooks and cranny of the dataset, scrubbed it till it’s squeaky clean, and now your data is ready for the real action — machine learning.
The next step is in selecting the best machine learning model. You would fit the data on a variety of different models, and perform some hyperparameter search.

If you’ve been there, chances are you have written the same calls to common machine learning packages like sklearn many, many times across different projects.
A regression problem? Maybe you would sample from linear regression, decision tree, and support vector machine.
A classification problem? We would try classification algorithms like logistic regression, decision tree classifier, naive bayes, and boosting algorithms.
Truth is, you’ve written the code so many times, and you’re not learning much from writing the same code. Also, it takes up the valuable time that you could spend generating insights from the model…
What if we can automate the most tedious part of this modeling process? What if we can explore thousands of possible pipelines to find the best one for our data?
Introducing TPOT, your machine learning assistant.
TPOT stands for Tree-based Pipeline Optimization Tool. TPOT is a Python Automated Machine Learning tool that optimizes machine learning pipelines using genetic programming.

Which part of the machine learning pipeline can TPOT automate?
More concretely, TPOT helps with the process of
- feature selection
- feature preprocessing
- feature construction
- model selection
- parameter optimization
Here’s where TPOT can help in the machine learning pipeline.
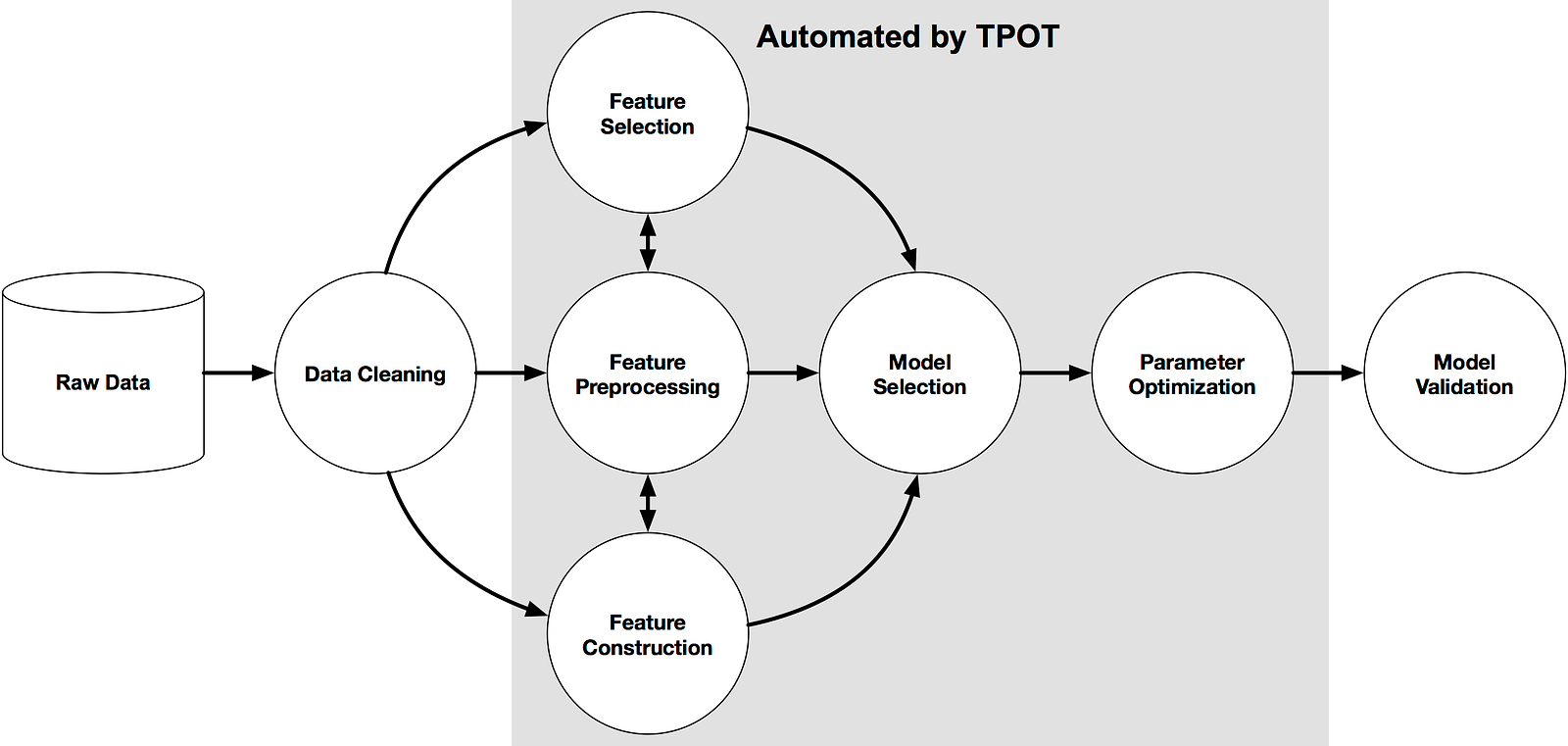
What problems can TPOT solve?
TPOT has been shown to perform very well on classification and regression tasks. Here are some examples:
- Iris Dataset Classification
- Boston Housing Prices Regression
What algorithms does TPOT sample from?
By default, TPOT searches over a broad range of preprocessors, feature constructors and selectors, models, and hyperparameters that minimizes the model predictions error.
For classification problems, it searches over the following:
- linear models (like Logistic Regression)
- naive bayes models (like Bernoulli NB, Gaussian NB, MultinomialNB)
- tree models (like Decision Tree Classifier)
- ensemble models (like Random Forest Classifier)
- SVM models (like LinearSVC)
- XGBoost models
For regression problems, TPOT’s search space includes:
- linear models (ElasticNetCV, SGDRegressor),
- ensemble models (like GradientBoostingRegressor)
- neighbor models (like KNeighboursRegressor)
- SVM models (like Linear SVR)
- XGBBoost models
TPOT Sample Code
Of course, before we start, let’s install TPOT on our environment.
pip install tpotThe following code uses the Titanic dataset as an example for TPOT.
from tpot import TPOTClassifier
from sklearn.model_selection import train_test_split
import pandas as pd
import numpy as np
# reading in the data
titanic = pd.read_csv('data/titanic_train.csv')
# Train-test split
training_indices, validation_indices = training_indices, testing_indices = train_test_split(titanic.index, stratify = titanic_class, train_size=0.75, test_size=0.25)
# Calling the TPOT Classifier
tpot = TPOTClassifier(verbosity=2, max_time_mins=2, max_eval_time_mins=0.04, population_size=40)
tpot.fit(titanic_new[training_indices], titanic_class[training_indices])
# To get the score
tpot.score(titanic_new[validation_indices], titanic.loc[validation_indices, 'class'].values)
# Export the pipeline as a python file
tpot.export('tpot_titanic_pipeline.py')Running this for an hour or so, we find that a Random Forest performs the best at the classification.
In `tpot_titanic_pipeline.py`, we would find the best trained pipeline. This is the pipeline that can be copied to wherever you need to reuse the model.
import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
# NOTE: Make sure that the outcome column is labeled 'target' in the data file
tpot_data = pd.read_csv('PATH/TO/DATA/FILE', sep='COLUMN_SEPARATOR', dtype=np.float64)
features = tpot_data.drop('target', axis=1)
training_features, testing_features, training_classes, testing_classes = \
train_test_split(features, tpot_data['target'], random_state=None)
exported_pipeline = RandomForestClassifier(bootstrap=False, max_features=0.4, min_samples_leaf=1, min_samples_split=9)
exported_pipeline.fit(training_features, training_classes)
results = exported_pipeline.predict(testing_features)For more information about the TPOT API, please read the documentation here.
More Advanced Usage of TPOT
TPOT supports the use Dask for Parallel Training
For larger problems, parallel training will reduce the amount of time needed for the model to converge. This is where distributed training on Dask cluster can help significantly. To do so, simply use the use_dask=True command in the estimator, as such:
estimator = TPOTEstimator(use_dask=True, n_jobs=-1)
TPOT can be used on the command line!
The exported pipeline can be called from the command line to make predictions. Here’s an example.
tpot data/mnist.csv -is , -target class -o tpot_exported_pipeline.pyTPOT can be used to fit neural networks
TPOT can use built-in PyTorch neural network models as part of its model search.
To do so, one needs to explicitly instruct TPOT to do so. Here’s an example of a classifier that uses the neural network. You can use this line to replace the above TPOTClassifier line from the Titanic code above.
clf = TPOTClassifier(config_dict='TPOT NN',
template='Selector-Transformer-PytorchLRClassifier',
verbosity=2,
population_size=10,
generations=10)However, note that this is still in the experimental phase. Proceed with caution!
What’s not to love?
- As with AutoML tools, TPOT might take a while to run (up to hours!). Don’t lose patience when optimizing your model!
- TPOT might recommend different solutions for the same dataset. This is because TPOT’s optimization uses randomness in the search for the best pipelines. When this happens, you might want to check if TPOT has converged (give it a little more time, maybe?) or if the two pipelines have similar results.
- TPOT cannot perform unsupervised learning at the moment.
More resources on TPOT
These are supremely helpful in helping you get started!
Other AutoML tools
Here is a non-exhaustive list of Automated Machine Learning tools that you can explore, apart from TPOT
Conclusion
TPOT is extremely useful in finding a first optimized model for proof-of-concept projects. Sure, TPOT’s output might still require plenty of tuning, and is for sure not production-ready. Yet, it is good enough to show the first results and gather the momentum needed for future progress.
I love TPOT. I have used it in my work, and it saved me plenty of time that I instead used to derive insights from the model.
If you like this, you might also like my other posts where I explore concepts in machine learning.
I write posts like this.
Read more content like this on my blog here. Also, connect with me on LinkedIn! Would love to hear your experience on TPOT.

