How Are You Feeling? — Answered with A Real-Time Emotion Detector
A real-time emotion detector built with Python and OpenCV

‘How is he feeling?’ As conversations about mental health become more prevalent, this question occurs to me more frequently. Thanks to the Joker’s powerful portrayal of mental illnesses, we start talking about ways to maintaining good mental health.
Mood tracking is one of the ways to do so as it helps us to regulate our emotions. If we’re able to recognize a change in our mood patterns early, we can start taking steps to manage them.
That leads me to think… what if we can harness the power of machine learning to predict what someone is feeling on the inside — without having to ask a single question?
So I built my very own emotion detector (in this Github repository).


Here’s how.
The Process, Summarized
Firstly, I gathered a large data set of human faces with various emotions. Then, I trained a convolutional neural network to recognize various emotions using Keras. To predict emotion in real-time, the live video from a webcam is fed into a network which detects faces and predicts the emotions.
- Gathering The Data
The data used is the Facial Emotion Recognition data set. It consists of 35,887 48x48 grey-scale faces categorized into 7 types of emotions with a train-validation-test split of 75–12.5–12.5.

Let’s explore the distribution of our data. The frequency plot reveals that the data set is skewed. While there are over 9000 happy faces, there are fewer than 1000 ‘disgust’ faces. This tells us that we might not be able to recognize ‘disgust’ faces with effectively with this data set.

2. The Architecture
It is natural to consider the use of a convolutional neural network for the image recognition task. Compared to traditional machine learning techniques (such as Decision Tree or Gradient Boosting), a convolutional neural network allows features to be detected effectively. Such a network allows simple features detected early in the network (like lines) to be pieced together to form sophisticated features (like simple curve lines that make up a left eye), making a convolutional neural network particularly effective at recognizing images.
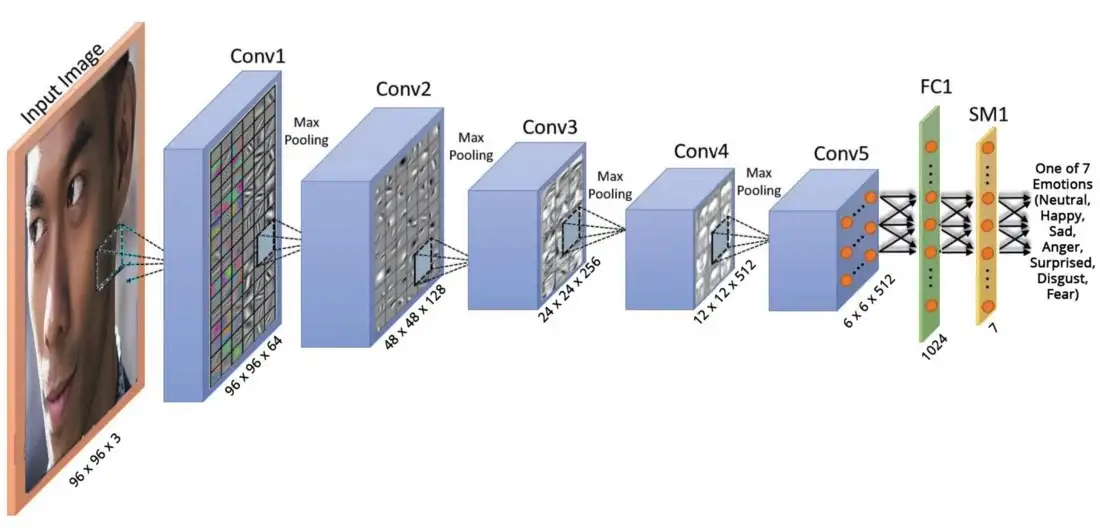
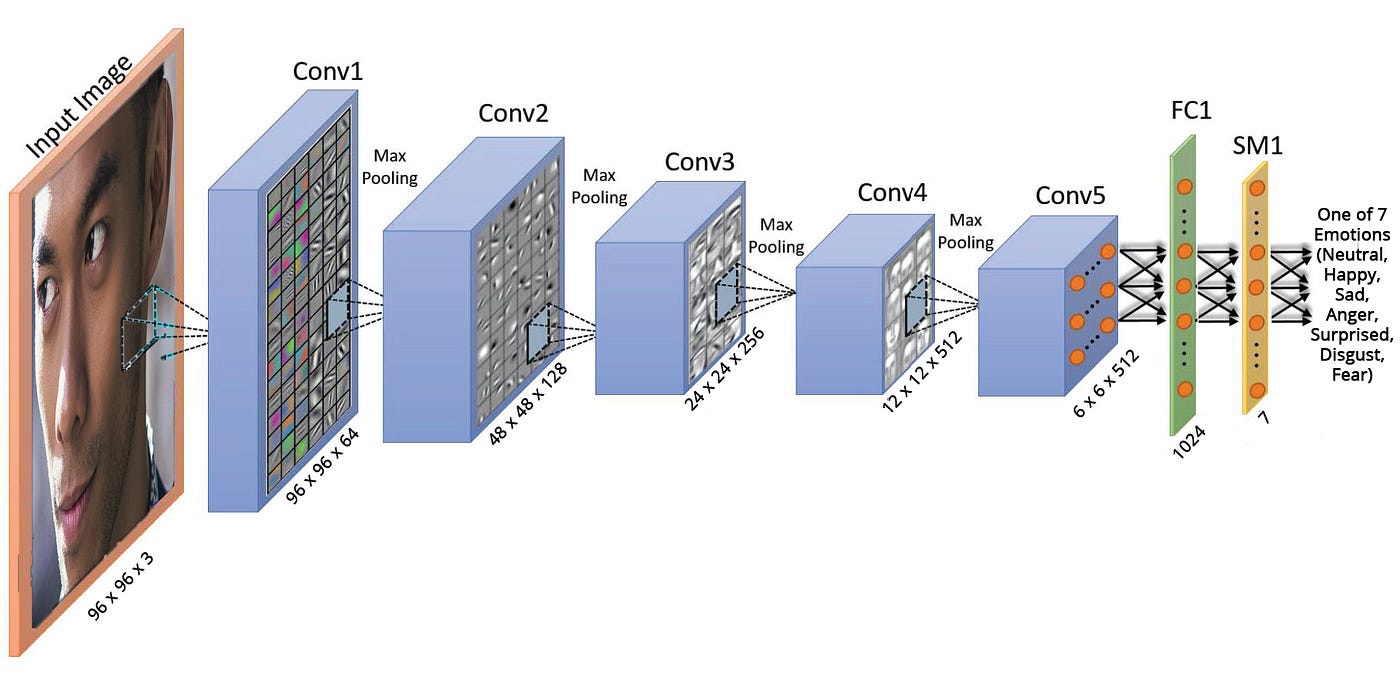
Thus, the architecture used here is a convolutional neural network called VGGFace proposed by a group of researchers at Oxford. The input of the network is fed into 8 convolutional blocks and 3 fully connected layers. Each of the convolutional blocks contains a linear convolution layer followed by non-linear layers (such as ReLU and max pooling). The final softmax layer outputs the probability of each type of emotion.
Considering the network takes in an input of size 226 x 226 is much larger than our training images of size 48 x 48, the network might over-fit to the training images. In other words, the network might memorize the faces in the training set — it might perform very well on faces it has seen before, but not on those it has not. Thus, the network is altered in two ways:
- Firstly, the number of convolutional blocks (Conv) is reduced from 8 to 5.
- Secondly, the number of fully connected (FC) layers is reduced from 3 to 1. Following this fully connected layer is a dropout layer with a probability of 0.5.
3. The Training Process
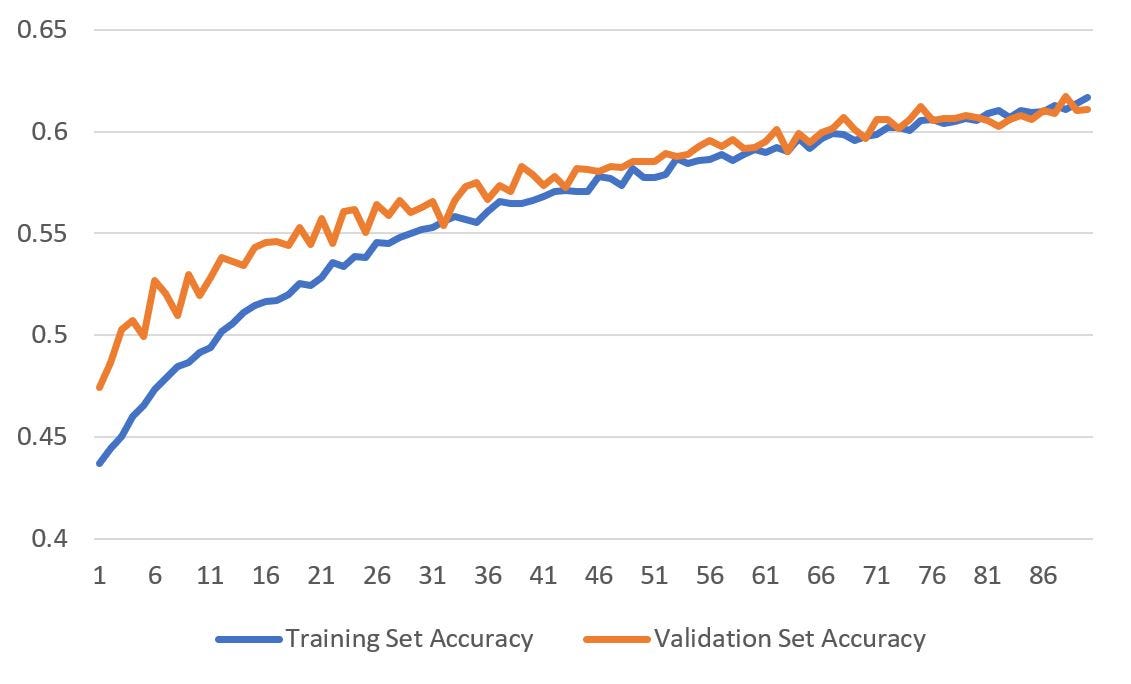
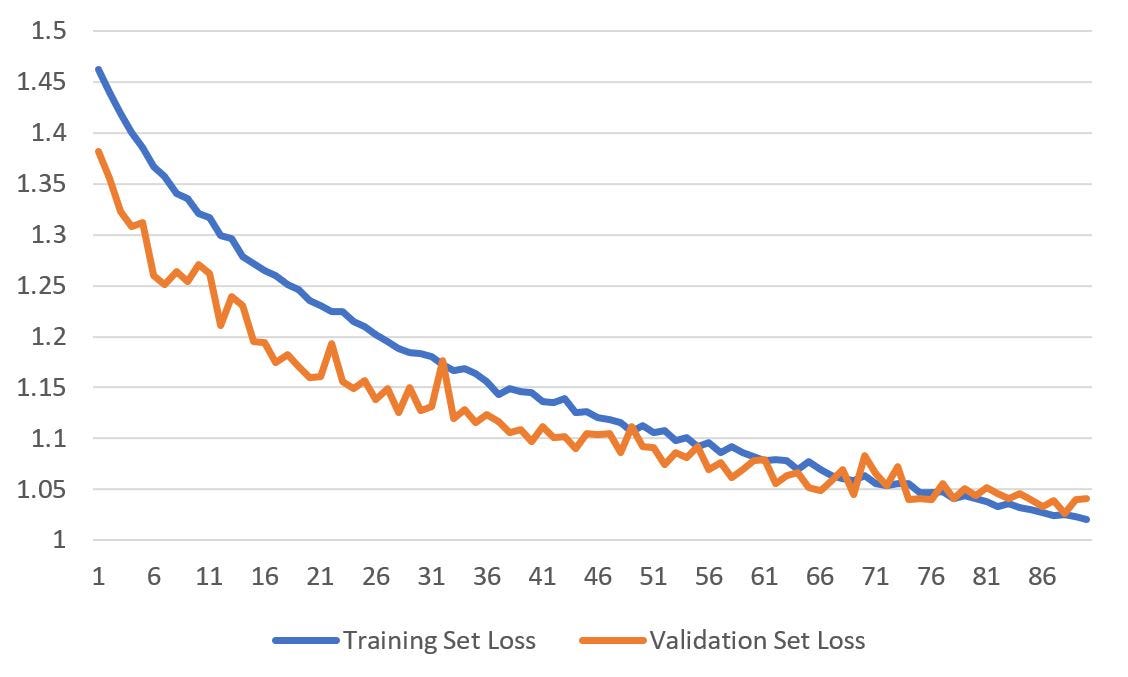
The model is trained using the deep learning library Keras. While training, the categorical cross-entropy loss is minimized with stochastic gradient descent at a learning rate of 0.001. The model was trained with 90 epochs, with a batch size of 32.
As training progresses, the accuracy of the model on training and validation sets increases while the losses decrease. Moreover, we see that the values for both the training and validation sets are very close to one another.
Put plainly, the performance of our model has increased on faces that it has seen before or otherwise. Voilà, that’s the sign of a healthy neural network.
4. The Performance
After training our model, we will test the model with a test set (with faces that the model has not seen before). Arguably, the performance of the model is best evaluated using F1-score of categorizing the emotion of a face, instead of metrics such as accuracy, precision or recall. Intuitively, accuracy is the proportion of the correct predictions made relative to the whole test set.
Accuracy of the test set = No of faces categorized correctly in the test set / Total number of faces in the test set.
However, a poor model may report high accuracy when the data set is skewed. For these cases, alternative metrics such as precision or recall are preferred. These two metrics can be combined into a single metric, the F1-score, which is particularly relevant for a model trained and tested on a skewed data set like FER2013.
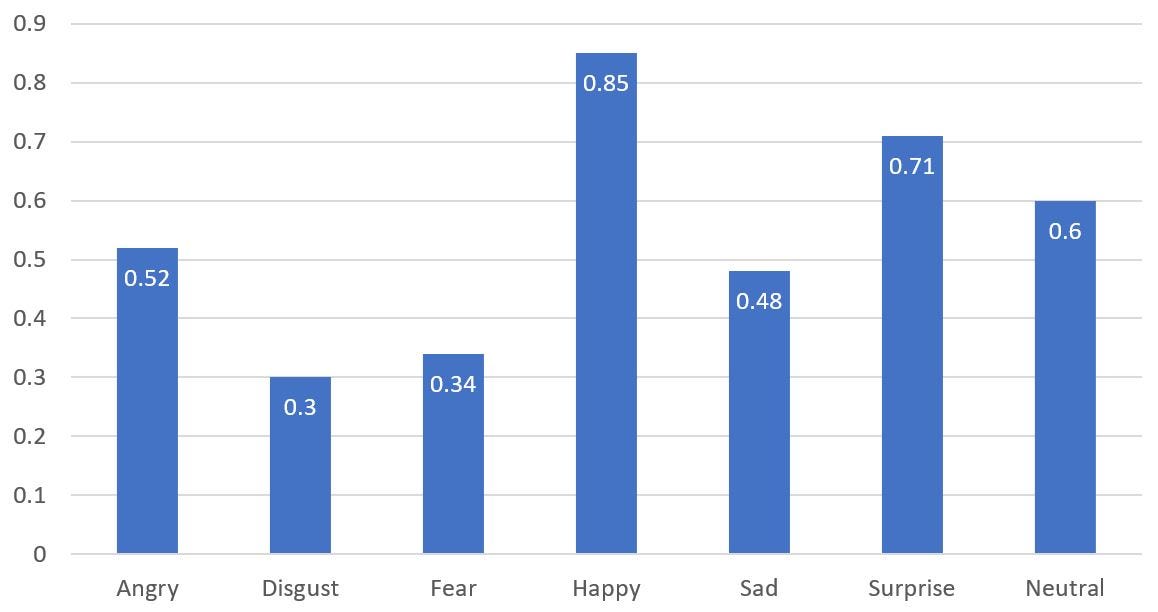
From this bar chart of F1-score, we can see that our model is capable of predicting happy, surprise, neutral, sad and angry faces decently. However, it performs poorer on faces that show disgust and fear. To investigate the cases of misclassification, we plot the confusion matrix for our data set.
The normalized confusion matrix reports the proportion of faces classified correctly or otherwise. On the vertical and the horizontal axes of the matrix are the true and predicted label of the faces respectively. The diagonal of the confusion matrix shows the proportions of faces classified correctly, and everywhere else faces classified incorrectly.

With the matrix, we can analyze why the model performs poorly on ‘disgust’ and ‘fear’ by looking at the row of confusion matrix where the true label is either ‘disgust’ or ‘fear’.
Ah, it is clear now. Most ‘disgusted’ faces are incorrectly predicted as angry, sad or fearful while most ‘fearful’ faces are incorrectly predicted as sad or angry. This should not come as a surprise, as the limited number of ‘disgusted’ faces in the training set might not be enough to train the model.
More importantly, more often than not, we express more than one emotion on our faces. A person can experience and express varying degrees of fear, sadness and anger — all with one expression. Thus, even a human may not be able to accurately distinguish the type of negative emotion from a face, let alone a machine. Needless to say, surpassing human-level accuracy is challenging though not impossible.
5. The Limitations and Improvements
What we’ve discussed is possibly the biggest limitation of the model. It is not able to squarely categorize the emotions we experience into 7 neat little boxes — simply because we experience more than 7 emotions, and an (arguably) infinite combination of them. Thus, a better version of this model should recognize a combination of different emotions. For instance, if a face expresses both sadness and anger, both emotions are shown as the output. This can be done by setting a probability threshold — as long as the probability of a particular emotion is higher than the threshold, it is shown as one of the outputs.
Another clear limitation of the model is the use of a large network with many parameters that may limit its prediction speed. In fact, the modified VGGFace network (19.5 million parameters) is significantly larger than lighter networks like MobileNet (2.3 million parameters). Other models worth exploring are LightFace and SqueezeNet, both of which are lightweight models used for computer vision.
6. Prediction in Real-Time
In order to predict in real-time, the live video feed is first captured using CV2 on python and fed into a face detection network, MTCNN, which can achieve superior performance in real-time. The face detected is then fed into our trained network, where the model outputs the prediction.
7. The Next Steps
I am very excited to continue improving on the model’s limitation and eventually deployed to an app. In particular, I am interested in exploring building an app that can detect the downswings of a users’ mood based on camera images. Being able to detect negative emotions early, the app can help elevate users’ mood — through meditation, exercising or otherwise. To build the app, I plan to follow the foot steps of Laurence Monorey from deeplearning.ai in using Tensorflow Lite.
If you are interested in the project code, feel free to refer to my Github repository. I welcome any feedback :)
travistangvh/emotion-detection-in-real-time
The following repository is a real-time face detection and emotion classification model.
github.com
Acknowledgement
- Deep Face Recognition by Parkhi et. al.
P.S. This is my first deep learning project, and I’m incredibly happy that it worked out. I encourage anyone out there to experiment with new projects and try do the same.


