Probability vs Statistics for Data Science and Machine Learning
What’s the difference and why data scientists should know them


Probability and statistics — which comes first?
We almost always discuss probability and statistics hand-in-hand.
In fact, it is not uncommon for students to not know the distinction between statistics and probability.
But which comes first? What are the differences even?
It’s a chicken-and-egg problem. You can’t have probability without statistics, and vice versa. What do I mean by that? I’ll explain more in this post.
In this short post, I will highlight some of these differences between probability and statistics and some applications of probability and statistics in data science.
From this, I hope you will gain or have a new perspective of why data scientists need to know probability and statistics.
Probability
Probability is the branch of mathematics concerning numerical descriptions of how likely an event, like a coin flip, is to occur according to Wikipedia.
Let’s continue with the example of a fair coin flip.
We do not have the data of what actually is going to happen, but we can still answer the following using probability —
- What is the probability that the next coin flip is a head?
- What is the probability that the out of 5 flips, 3 turn out to be heads?
- What is the probability that we will flip the coin 9 times before we see a tail?
These questions in probability show us the following —
model
Here, the ‘model’ of the coin flip is that the coin is fair, i.e. the probability of it landing on a head or tail is 50%. We assume that this model is correct and reflects the truth.
As we use the probability model, we do not have the data on what is actually going to happen, but we can quantify what we expect is going to happen.
To summarize, in probability, we predict how likely future events are based on a model without actual data.
Statistics
This summary of probability contrasts with statistics. In statistics, we infer the truth or the model based on the actual data observed.
In fact, statistics is a form of mathematical analysis that uses quantified models, representations and synopses for a given set of experimental data, according to Wikipedia.
Note the emphasis on ‘a given set of experimental data’. Doing any statistical work requires us to start with a set of data.
Now, we are given a coin which we know nothing about. Suppose that out of 100 coin flips, we observe 90 heads and 10 heads, we can answer the following using concepts from statistics:
- Is the coin fair? (probably not)
- How confident are we that the coin is not fair? (quite)
- What is the actual probability of getting a tail from the coin? (most probably 10%)
From here, we see that
In statistics, we look at the set of data given to us, and then we make an inference of what is the model that is used to generate this set of data.
In this example, we do not know the truth about the coin, like in the case of probability. Instead, we know some data about the coin, we look back in time to make an inference about the coin.
Probability vs Statistics

I like to see statistics and probability as different ends of two coins —they are inherently related but opposite of one another.
- Probability goes from model to data, while statistics data to model.
- Probability is about looking forward (making predictions based on truth), while statistics is about looking backwards (understanding truth based on event).
In fact, these differences are summarized elegantly by Persi Diaconis, a Professor of Statistics at Stanford University —
probabilitystatistics
Probability and Statistics

Now that we have compared probability and statistics, can we also see how probability and statistics are related?
Probability and statistics are bedfellows. One typically learn probability before building on that knowledge to learn statistics — and probability is the stairway to statistics. A strong understanding of statistics will also enhance one’s appreciation of probability.
In one of my favourite lectures by Prof Tsitsiklis in 6.431x Probabilistic Systems Analysis and Applied Probability, he described the relationship between probability and statistics —
Probability, at the minimum, gives us some rules for thinking systematically about uncertain situations. If our probability model has some relation with the real world, then probability theory can be a very useful tool for making predictions and decisions that apply to the real world.
[1]
This relationship is summarized in this chart below.
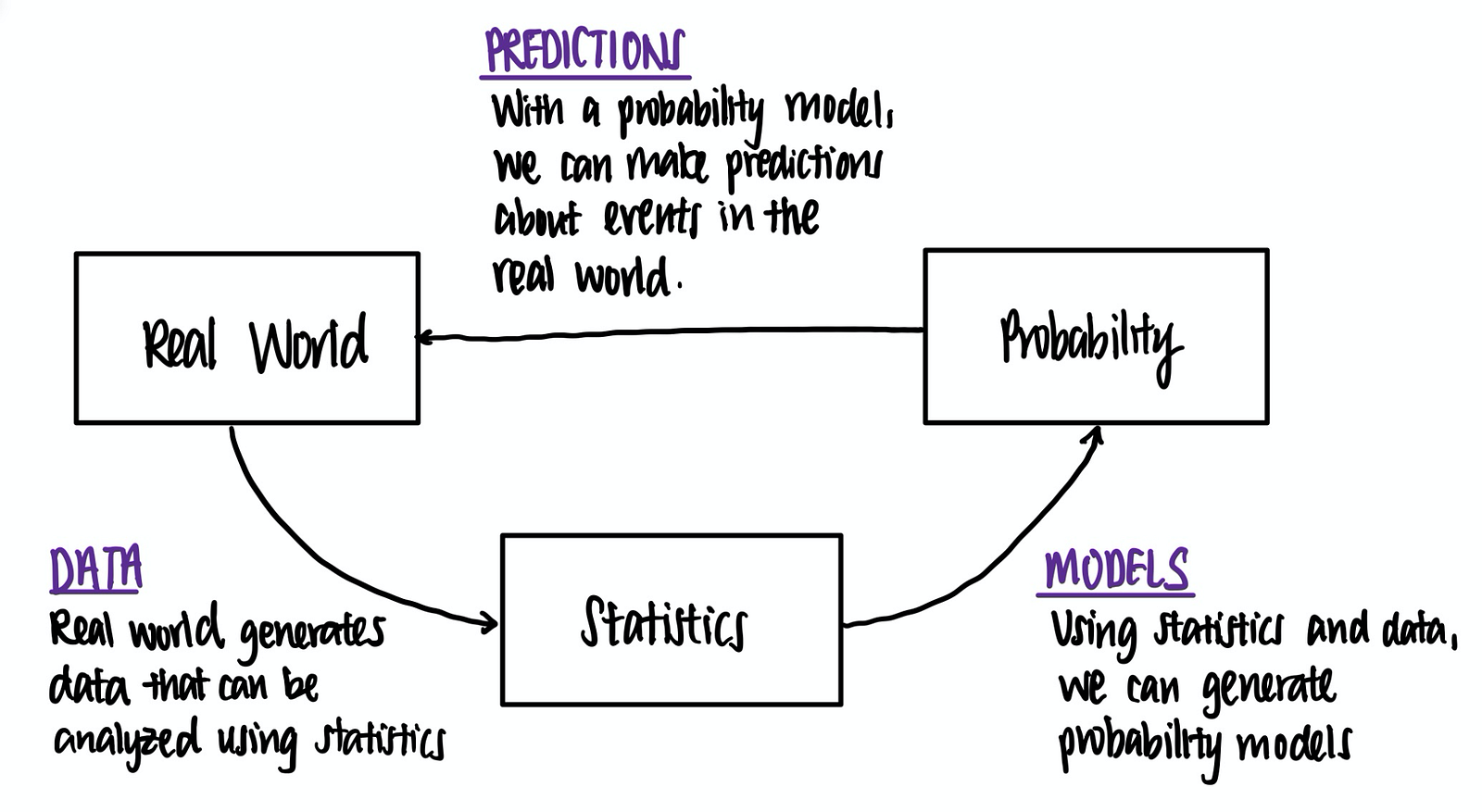
Probability, Statistics, Data Science and Machine Learning
Here, I will outline some cases where probability and statistics are essential for data scientists.
- Planning A/B Tests or Experiments
To understand an AB test, one needs to understand the concept of p-value, a concept in probability that tells us the probability that the null hypothesis is wrong when it is in fact correct. To obtain an intuitive understanding of p-value, one needs strong fundamentals in probability.
Another step in AB testing is to obtain the sample size for the experiment. In order to generalize the result from the experiment to the population at large, a proper sampling plan is required. To calculate the required sample size, one needs to understand the concepts of power and the types of errors in an experiment, concepts covered in statistics.
2. Machine Learning Modeling

Moreover, unbeknownst to many aspiring data scientists, the theoretical underpinning of machine learning is essentially advanced statistical concepts and mathematics. Many machine learning models are built on the assumption that the data follows a particular type of distribution.
Without understanding probability, a data scientist will not be able to decide if the data fulfils the assumption of the machine learning model and therefore might not make the best choice in the machine learning model.
For instance, a linear regression model assumes that the noise of each data point follows a normal distribution. To understand what means, a data scientist should know what a normal distribution is — which is what you learn in probability.
Thus, whether you are running a regression, classification or clustering model using vanilla machine learning methods or deep learning methods, you cannot run away from statistics.
Where To Learn Probability in Data Science
For the new learner who also wants to pick up programming and coding, HarvardX’s Data Science - Probability (PH125.3x) on Datacamp* will provide a gentle introduction to probability while allowing you to implement probability in R. Moreover, this also comes with a motivating case study on the financial crisis of 2007–08 — potentially a project that you can further work on and showcase on your portfolio.
For the advanced learner, I suggest taking the HarvardX Stat 110: Introduction to Probability*. This class is by far one of the most rewarding I have attended. Professor Blitzstein, one of my favourite professors for probability, covers the topics rigorously and intuitively.
There’s also a complete guide here —

Where To Learn Statistics in Data Science
For the new learner, I recommend taking the EdX Basics of Statistical Inference and Modeling using R*. This class is meant for new learners with limited statistical background and little practical experience. It aims to give the students the understanding of why the method works (theory), how to implement it (programming using R) and when to apply it (and where to look if the particular method is not applicable in the specific situation).If you prefer
For the advanced learner, I suggest taking the MITx: Fundamentals of Statistics*. This class is rigorous and is set at a graduate level for the ambitious learner who wants to understand advanced concepts including goodness-of-fit tests, General Linear Models, and Principle Component Analysis, on top of the typical statistics topics mentioned above.
All the classes mentioned here can be audited for free. If you like the class, you can pursue a verified certificate to highlight your knowledge in probability.
Conclusion
Probability and statistics are essential parts of data science. In fact, according to the IBM Data Science Skills Competency Model, the following are 2 out of the 28 major competencies of a data scientist.
Understand probability theory and probability distributions
Demonstrate knowledge of inferential statistics
They’re both important to a data scientist. So, it’s always a good idea to learn both of them hand-in-hand.
Feel free to connect with me if you have any questions, or simply want to learn data science together.

This is part of a series on probability. It’s bite-size data science that you can learn now in 5 minutes.
- Probability Models and Axioms
- Probability vs Statistics (you’re here!)
- Conditional Probability (coming soon)
- Bayesian Statistics (coming soon)
- Discrete Probability Distribution (coming soon)
- Continuous Probability Distribution (coming soon)
- Averages and the Law of Large Numbers (coming soon)
- Central Limit Theorem (coming soon)
- Joint Distributions (coming soon)
- Markov Chains (coming soon)
References and Footnotes
[1] John Tsitsiklis. 6.041 Probabilistic Systems Analysis and Applied Probability. Fall 2010. Massachusetts Institute of Technology: MIT OpenCourseWare, https://ocw.mit.edu. License: Creative Commons BY-NC-SA.
*These are affiliate links to courses that I recommend. This means that if you make a purchase after clicking the links, I will receive a percentage of the fees, at no additional cost to you.

