Teach Yourself Data Science in 2021: Math & Linear Algebra
Useful Courses and Resources for Machine Learning


Recently, I graduated from Chemical Engineering and got in my first role as a data analyst in a tech company. Since then, as I spoke to students from my school about the move, many expressed the same interest and the same question…
‘How did you move from engineering to data science?’
That was the exact question I ask myself — how can I make the move? That same thought bugged for and pushed to start pursuing the skills of a data scientist a little over a year ago. Of which, mathematics is one of the key skill sets of a data scientist.
But first, let’s understand…
What is data science?
This is a question with lots of ambiguity. To me, the definition that I agree most is this —
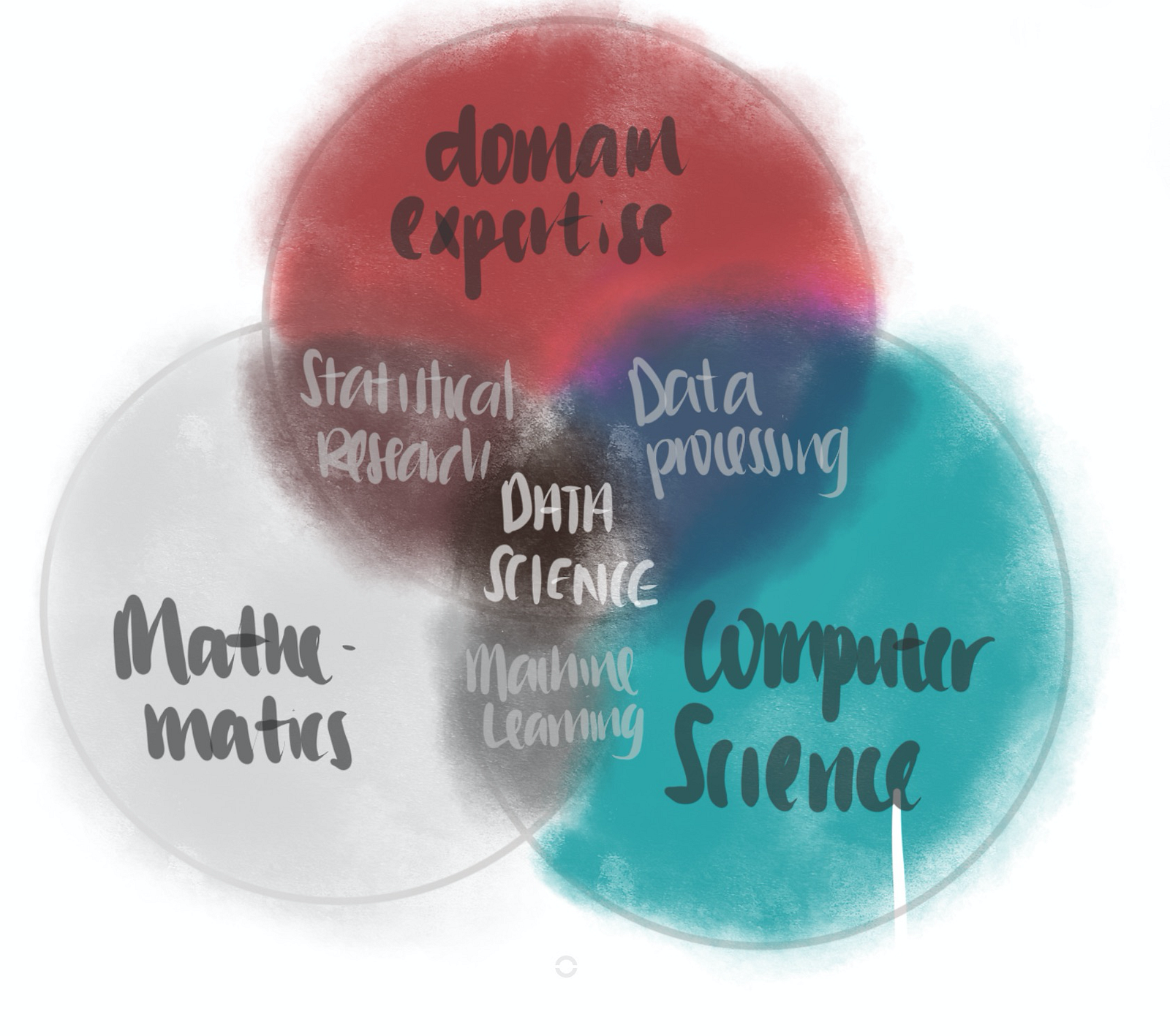
Data science is the inter-disciplinary field that uses techniques and theories drawn from the fields of mathematics, computer science, domain knowledge. [1]
Okay, so how do I learn data science?
In this series of blog posts, I’ll highlight some of the classes that I have taken along the journey, along with their pros and cons. Through that, I hope to help people who were in my shoes in planning their self-learning journey in data science. These posts are:
- Part 1 — Data Processing with SQL, Python and R
- Part 2 — Mathematics: Linear Algebra (you’re here!)
- Part 3— Probability and Statistics
- Part 4— Computer Science Fundamentals (coming soon)
- Part 5— Machine Learning (read it here!)
In this post, I will highlight how I learnt about the linear algebra required for data science. Specifically, I will highlight
- what linear algebra is
- how to learn linear algebra
- why it is important to data scientist
Linear Algebra: What is it
Linear algebra is the branch of mathematics concerning linear equations and their representations and through matrices.
In 2-dimension, it can take the form of a innocuous, vanilla straight-line formula y=mx+b. In higher dimensions, linear algebra becomes a little more challenging using the toolbox of linear algebra.
A study of linear algebra generally consists of vectors, matrices and
Vectors and spaces
A vector is a way of representing a quantity that has a direction.
For instance, if a boat is moving north-east 5 miles per hour, we can represent the vector of the boat’s velocity as a 5-unit long vector in the north-west direction.
A n-dimensional vector exists in, you guessed it, n-dimensional space. For instance, the boat can be simplified into an object that exists in 2-dimensional space —the north-south dimension and east-west dimension.
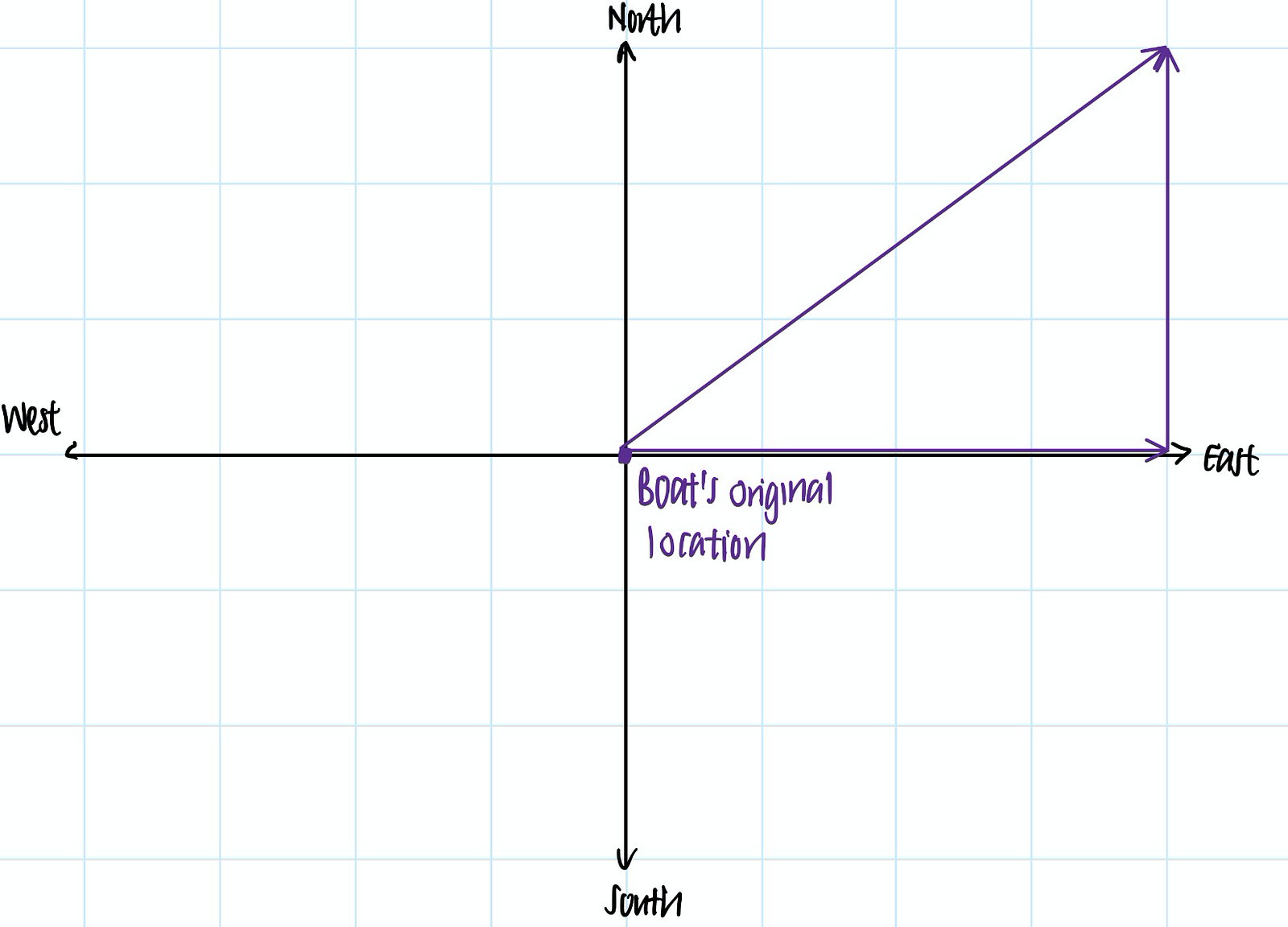
In the past hour, we can imagine that the boat has moved 3 miles north and 4 miles east, such that it is moving 5 miles per hour in the north-east direction. We can then imagine that the boat’s velocity vector as x = [3, 4].
To start learning linear algebra, we need to start understanding what are the properties of vectors (linear dependence or independence), what we can do with them (dot and cross products), and the properties of the spaces they exist in (subspaces).
Matrix transformations
If we combine several vectors together, we get a matrix. Matrices can be interpreted as a transformation to vectors, like scaling, rotation or rotation. Imagine we want the boat to travel twice as fast in the same direction (represented by new vector y), we would scale the boat’s velocity vector by two using the matrix A, with the formula:
y = A xEach matrix has its own properties. One of the most important properties is the eigenvector, which is the vector that does not change in direction after the transformation is applied. Another important property is the eigenvalue, which is the change in length of the same vector after that transformation.
This eigenvector is incredibly useful in advanced treatment of the subject, forming the cornerstone of many techniques used including Principle Component Analysis and Singular Value Decomposition.
Linear Algebra: Where I Can Learn It
Let’s face it. Linear algebra is a difficult subject. So, here I’m providing linear algebra resources for different levels of knowledge on mathematics one already has.
Very new to math? Start with the simpler resources. Already know most of it? Give yourself a challenge with challenging courses.
Basic: Datacamp’s Linear Algebra for Data Science in R*
This short class provides an introduction linear algebra — with code! This is suited for a learner aiming to wants to improve their proficiency in R while picking up simple introduction to linear algebra.
Level of difficulty: ★
Time commitment: 4–6 hours
Cost: Free for introductory chapter; subscription needed for next chapters.
Basic: 3Blue1Brown’s Essence of Linear Algebra
This YouTube series is a must-have resource to get started with linear algebra. It provides a visual introduction to linear algebra without resorting to mathematical jargons. Concise and intuitive, this series prepares learners for the intermediate / advanced classes below.
Level of difficulty: ★★
Time commitment:~4–6 hours
Cost: Free
Intermediate: Khan Academy’s Linear Algebra Series
Taught by the author of 3Blue1Brown on YouTube, the Linear Algebra series on Khan Academy is one of the reasons why I fall in love with Khan Academy. It is easy to understand. As per 3Blue1Brown’s style, this series provides intuition of linear algebra through engaging visuals.
While this series is engaging, it does not provide exercise for learners to practice their skills after learning the concepts. Moreover, it does not dwell into more advanced concepts such as LU decomposition, symmetric matrices, Singular value decomposition, among others.
Level of difficulty: ★★★
Time commitment:~15–20 hours
Cost: Free
Intermediate — Advanced: Imperial College’s Linear Algebra for Machine Learning
More advanced than Khan Academy’s video lecture is Imperial College’s Linear Algebra course. In addition to all the concepts covered by Khan Academy, this Coursera class also provides a cursory introduction to the topics missing from Khan Academy.
It warms the learners up with concepts starting from vector and matrices before introducing more advanced operations like matrix transformations. It also provides a visual understanding of linear algebra.
Moreover, the programming assignments are in python and uses the numpy package extensively. It is an excellent practice for those who want to improve their proficiency in numpy.
Level of difficulty: ★★★★
Time commitment: ~19 hours
Cost: Free, or $49 for access to assignments, quizzes and certificate.
Advanced: GeorgiaTechX’s Linear Algebra Series*
The intermediate series above generally do not provide an in-depth treatment of the more advanced concepts. If you’re hungry for more rigorous math, you might want to consider GeorgiaTech’s Linear Algebra 4-part series.
This 4-part series has the same syllabus as the GeorgiaTech’s on-campus MATH 1554 — so you know you are getting the GeorgiaTech rigour!
Instructed by Prof Greg Mayer, this series goes through different topics in linear algebra comprehensively. These includes vectors, matrices, determinants, diagonalization, symmetric matrices, and singular value decomposition, among others.
GeorgiaTechX’s series earns cookie points for those who would like to show off their knowledge in linear algebra with a shareable certificate at $199 for each certificate.
Level of difficulty: ★★★★★
Links: Part 1 | Part 2 | Part 3 | Part 4
Time commitment: 3 weeks per part. Total of 12 weeks.
Cost: Free, or $199 for certification.
Advanced: MIT’s 18.06 Linear Algebra Series
18.06 was taught by Prof Gilbert Strang, one of the most respected professors in the realm of mathematics. This class has been touted by many as the de-facto linear algebra class for the serious learner. After taking the class, I find those remarks unsurprising, since his class is intellectually engaging, conceptually deep and needless to say very challenging.
MIT’s 18.06 is made freely available on MIT OpenCourseWare, which also contains the video lectures, assignments, quizzes, and exams.
Unfortunately, a completion of the class does not earn you any certificates. For that, you might want to use GeorgiaTechX’s series or Imperial College’s Coursera class above. Alternatively, you can always implement your own project in linear algebra
Level of difficulty: ★★★★★
Time commitment: Total of 12 weeks.
Cost: Absolutely free with no strings attached.
Linear Algebra: Why it is Important to Data Science and Machine Learning
As a mathematics-intensive domain, data science applies linear algebra techniques to transform and manipulate data sets effectively.
In particular, data scientists use linear algebra for applications like vectorized code and dimensionality reduction, among others.
Vectorized Code
Linear algebra is useful to produce vectorized codes that are more efficient than their non-vectorized counterparts. This is because vectorized codes produce the results in one-step, while non-vectorized counterparts typically use multiple steps and loops to arrive at the same answer.

For instance, we would like to find find out the temperature based on the number of chirps of a cricket (yes, you read it right, it’s crickets.)
The equation that relates the temperature with the number of chirps
T = 50+[(N — 40)/4]
T = temperature
N = number of chirps per minute
Suppose we collected several data points on the number of chirps per minute — 45, 50, 55, 58. How do we find the temperature?
We can substitute 45, 50, 55, 58 into the equation T = 50+[(N — 40)/4]. This would take 4 steps:
T = 50 + [(45–40)/4] = 51.25
T = 50 + [(50–40)/4] =52.5
T = 50 + [(55–40)/4] =53.75
T = 50 + [(58–40)/4] =54.5
… I’m bored by myself just typing this.
Imagine if we have 1000 data points that we to process. You will not want to perform the make 1000 substitutions because that’s highly inefficient.
Linear algebra provides an alternative to this by allowing us to represent the equation T = 50+[(N — 40)/4] in matrix form and make calculation in one-step as such.
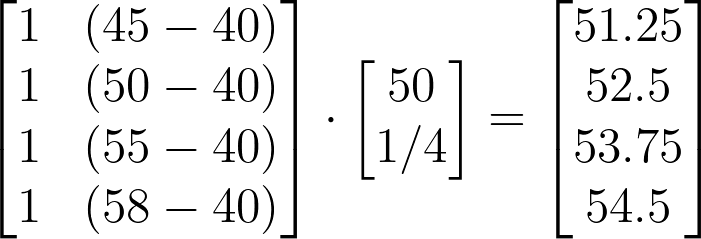
What an elegant operation. Now, even if we millions of data points, we can find out all the outputs in one step.
numpy, which is the python’s package for manipulating arrays, make use of vectorized operations to allow for more optimal mathematical operations. That’s why numpy is lightning fast when compared to for loops!
Dimensionality reduction: Principle Component Analysis

Another reason why linear algebra is so important to data scientist is its application in dimensionality reduction using a technique called Principle Component Analysis (PCA).
Dimensionality reduction is an important step in preprocessing of data sets used for machine learning purposes. This is especially so for large data sets, i.e. those a large number of features / dimensions. At times, many of these features may be highly correlated with one another.
Put simply, given a large data set with n features, PCA identifies a new set of m dimensions (where m ≤ n) to describe the same data set, with as little loss of information as possible.
By perform dimensionality reduction on a large data set, we improve the speed efficiency of the machine learning algorithm. This is because the algorithm needs to only look at a fewer features before making one prediction.
Linear Algebra in Machine Learning
Linear algebra is an important tool to implement machine learning optimization.
When training a machine learning algorithm, what are doing is really finding the minimum of the loss function. Modern machine learning uses gradient method descent to do so, which is a way of slowly going to the minimum of loss function based on the steepness of the function. With gradient descent, we will not find the exact minimum, but somewhere close enough.
On the other hand, linear algebra provides a closed-form formula to find the minimum of the loss function, provided if the system is linear. This means to say that we can find the exact minimum with linear algebra.
Both have its pros and cons, but both are equally important for a strong understanding in optimization of machine learning algorithm.
Conclusion
Learning these resources made me much more confident in data science as they provided me with a great foundation to learn other machine learning and data science concepts.
All the best to your learning journey! Feel free to reach out to me via LinkedIn for any suggestions or questions.
You might also like…
- How to be a Data Analyst — Data Viz with Google Data Studio
- 4 Steps to be a Great Data Analyst — Don’t be a Query Monkey
Disclaimer
Links with an asterisk are affiliate links. You can use the affiliate link to sign up for the class at no additional cost to you.

